By Alastair Doggett, Senior Machine Learning Engineer
Legal language rarely resolves neatly within a single sentence. Clauses can span multiple paragraphs, key obligations are scattered across sections, and nuance lives not in isolation, but in contextual accumulation. And yet, much of today’s contract AI still relies on single-sentence classification objectives.
At Ontra, we decided to challenge that paradigm — not by abandoning our current framework, but by expanding its scope. Leveraging our richly labeled corpus of contract data, we’re building a new generation of models grounded in multi-sentence span prediction: a more expressive and generalizable approach to understanding legal documents at scale.
Why single-sentence objectives fall short
Single-sentence classifiers have been foundational to contract intelligence systems. They work well for pinpoint questions like: What is the governing law? Is there a termination clause?
But single-sentence classifiers fall short when:
1. Context spans multiple sentences.
Many legal obligations or exceptions are expressed over multiple lines or clauses. A classifier that evaluates sentences in isolation loses access to the broader framing and dependencies that determine legal meaning. For example, the main obligation appears in one sentence, while a carveout or condition might appear in the next — understanding one without the other leads to incorrect conclusions.
2. Class labels are sparse or imbalanced.
In many legal tasks, the answer we’re looking for (e.g., a carveout, a specific exception, or a defined trigger) is rare. Most sentences are irrelevant to a given question. Classifiers trained on highly imbalanced data can overfit to the negative class and fail to surface subtle but important positives. Worse, they may need heavy rebalancing or manual thresholds to behave reasonably at scale.
3. Precision around where the answer lives is as important as what the answer is.
Legal questions like “Does this indemnification clause carve out gross negligence?” can’t always be resolved by classifying a sentence in isolation. These answers often span multiple phrases or clauses. Accurate answers require identifying and bounding the relevant span — not just labeling that something is present.
Using labeled highlights to learn span behavior
Our insight was simple: Ontra already maintains a large corpus of clause-level highlights from Ontra’s Legal Network — spans of text tagged to answer complex scorecard questions. These are more than binary labels; they’re bounded intervals of legal meaning, rich with positional and semantic information.
So, rather than classifying sentences, we reframed the problem: “Given a document and a question, predict the start and end indices of the answer span.”
This shift opens the door to more powerful, explainable, and adaptable models.
Constructing the span prediction framework
We formalized this problem using a pair of canonical evaluation metrics:
Jaccard Similarity – Proportional Agreement
Imagine a model highlights a portion of a clause to suggest an edit. We compare that highlight to a human-edited version. Jaccard Similarity asks: “How much overlap is there between the two selections, relative to the total coverage?”
Formally:
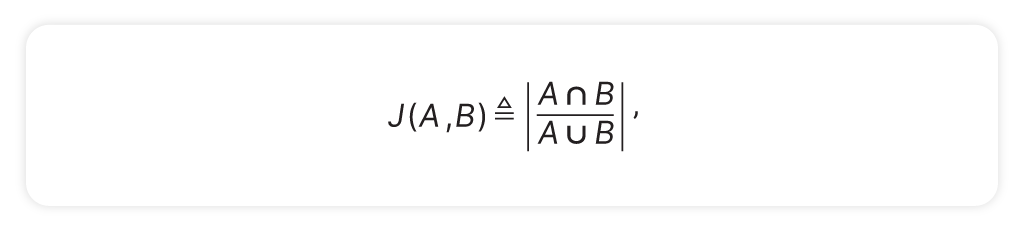
where A, B are highlights represented by compact (closed and bounded) intervals of index spans.
Hausdorff Distance – Boundary Sensitivity
Contracts are sensitive to the *edges* of clauses. Leaving in or out a single phrase—”to the best of Recipient’s knowledge,” for example—can materially change the meaning of a term.
Hausdorff Distance quantifies how far apart the endpoints of the model and human-selected spans are:
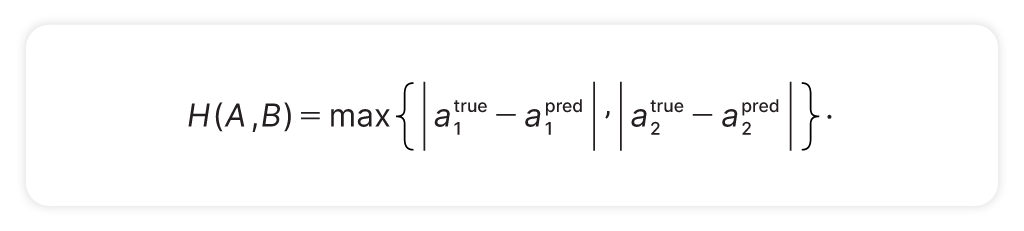
Together, these metrics define our problem space — a mathematically tractable representation of multi-sentence clause prediction.
From classifiers to span models
To baseline our approach, we embedded our production single-sentence model into this new span-based framework.

This allowed us to quantify its performance in a higher-dimensional setting, creating a clean reference point for improvement.
From there, we built a custom span prediction model inspired by BiDAF, a well-known architecture from question answering:
- Static query framing (the question doesn’t change)
- BiLSTM context encoder
- Start and end index prediction heads
- Optional components like character-level embeddings and highway networks
Instead of saying, “This sentence contains the answer,” our model learns where the answer begins and ends across sentence boundaries.
Training with precision, visualizing with insight
We trained an in-house span prediction model from scratch using a token-level loss function,
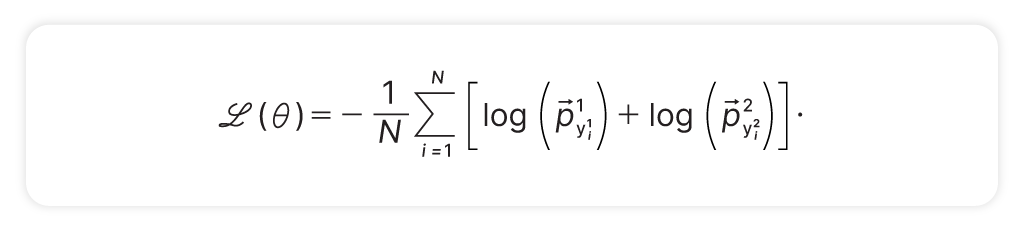
complemented by:
- Calibrated accuracy: Average confidence on correct span indices

- Live tracking of Jaccard and Hausdorff metrics

- Heatmaps of probability distributions over documents to diagnose behavior

These tools helped us interpret how the model was reasoning across spans — not just what it predicted, but why.
Field testing with real contracts
To evaluate the system in realistic conditions, we deployed an inference pipeline on production documents. Using attorney-labeled highlights as ground truth, we were able to perform batch inference:

An example across a single document for predicting the “Governing Law” span:

span_text:
This letter agreement shall be governed by and construed in accordance with the
laws of the State of New York, without giving effect to principles of conflicts
of laws.true_label: New York
doc_len: 1849
start_idx: 1387 ; start_prob: 0.94
end_idx: 1419 ; end_prob 0.91
These results suggest that span-based models can act with discipline and clarity, not just flexibility.
Why span prediction improves legal AI
Shifting from single-sentence classification to span-based modeling brings contract AI closer to how attorneys actually interpret legal documents: holistically, contextually, and with attention to detail across multiple clauses.
Unlike classifiers that output only a yes/no label, span-based models provide explicit boundaries, showing not just what the answer is, but where it lives and how it’s framed in the document.
Because span predictions are trained on a high-quality corpus of clause-level annotations, the model isn’t making educated guesses. It’s learning from real lawyer-validated decisions, emulating human behavior with clarity and accountability.
Final thoughts
This evolution from single-sentence tasks to multi-sentence span prediction reflects a broader shift in contract AI: from quick wins to domain-deep intelligence. As we continue to push into more complex questions, our models will need to do more than classify — they’ll need to comprehend.
That’s the frontier we’re building toward.





