Authors:
Jeffrey Hsiung, Senior Machine Learning Engineer
Shipra Arjun, Senior Machine Learning Engineer
Tony Wong, Senior Machine Learning Engineer
Nupur Agrawal, Machine Learning Engineer
How Ontra built a systematic evaluation framework for extracting answers from complex financial documents.
Summarizing credit agreements
At Ontra, our mission is to transform unstructured information into insight, action, and automation, including processing challenging financial documents like credit agreements for private markets firms.
Credit agreements are notoriously complex, often running hundreds of pages filled with dense legal language and interdependent clauses. For private credit firms and their internal legal teams, quickly summarizing and extracting specific information from these documents is critical for risk assessment, compliance monitoring, and decision-making. Yet the sheer volume and intricacy of these agreements make manual review not only time-consuming but also highly prone to error.
The same complexities that burden manual review also raise the risk of automation errors, demonstrating the need for a systematic quality-evaluation framework.
This article outlines how we created an automated workflow capable of summarizing complex credit agreements and how we built an evaluation framework to continuously measure and improve the summarization workflow’s performance. In real-world deployment, the systematic evaluation approach delivered:
- 93% retrieval recall
- 66% increase in high-accuracy outputs
- 46% F1 improvement
Problems with credit agreement summarization
At its core, credit agreement summarization is a question-answering (QA) task where we need to find precise answers to specific questions within a given text.
Questions might include:
- “Who is the lender under the agreement? Provide its full legal name.”
- “Is there any sort of leverage ratio within the financial covenants?”
- “Review the credit agreement and determine the maturity date of the term loan, if there is a term loan.”
- “With respect to the term loan, does an asset sale trigger a mandatory prepayment of the loan by the borrower?”
The challenge lies not just in answering these questions, but in ensuring they are accurate, complete, and properly grounded within the document’s legal framework.
To ensure these qualities in answers to the questions, we recognize there are two critical steps to evaluate:
- Retrieving the right context: Validating the retrieved context — meaning the specific text spans extracted from the document — ensures that each answer is supported in the document. This can be used to measure completeness because we can directly assess whether all relevant clauses, definitions, and cross-referenced provisions have been fully retrieved to answer the question.
- Generating grounded answers: Generating answers from these extracted spans ensures that the answer is grounded in the correct passages of the document that answers the question. Finally, accuracy can be measured because we can compare alignment in the model’s generated answer against the known ground-truth annotations in our evaluation framework.
Can’t I just ask ChatGPT?
Large language models (LLMs) continue to improve at a remarkable pace with impressive reasoning modes and growing context windows, some large enough to include entire credit agreements. However, prompting LLMs directly is insufficient for this type of work because these documents far exceed what models can reliably process or reason over in a single pass.
Even with large context windows, models struggle to track definitions, conditions, and amendments spread across hundreds of pages, leading to omissions, hallucinations, or misinterpretations.
Direct prompting also provides no guarantee of grounding. The models may generate plausible but unverified answers that do not appear in the document.
For instance, we asked ChatGPT 5.2 to ingest a publicly available credit agreement and answer questions about any mandatory prepayment triggers. At a glance, it appeared to answer the question credibly and in convincing detail; however, after asking for citations, the LLM backtracked and explained that it had inferred prepayment triggers. Indeed, a review of the credit agreement reveals these triggers to be fabricated.


Without structured retrieval, validation, and grounded answer generation, there is no way to ensure completeness, measure performance, or trace outputs back to source text. As a result, prompting alone produces outputs that are not reliable or auditable enough for high-stakes legal workflows.
The challenge: high stakes, specialized, and complex documents
Credit agreements are engineered to be precise, exhaustive, and internally consistent — properties that make them hard for humans to interpret and even harder for AI models. In practice, we’ve found several recurring challenges:
1. Extreme length and structural complexity
Credit agreements routinely span hundreds of pages and are organized into:
- Definitions, articles, sections, subsections, schedules, and exhibits.
- Layered definitions (“Applicable Margin”, “Consolidated EBITDA”, etc.).
- Separate documents (e.g., amendments) that are logically part of the same deal.
A single question — like “What is the maturity date of the term loan?” — may require jumping between:
- The definitions section
- The core term loan provisions
- Amendment or waiver sections that override prior terms
Any summarization system must navigate this structure instead of treating the document as flat text.
2. Highly specialized and conditional language
The language in credit agreements is:
- Domain-specific: Terms like “Material Adverse Effect,” “Permitted Liens,” or “Change of Control” have technical meanings and are often custom-defined.
- Conditional: Rights and obligations can depend on thresholds, ratios, or events (“so long as no Default or Event of Default has occurred…”).
- Layered with exceptions: A “yes” answer may be subject to so many carve-outs that, in practice, it behaves like a “no” for particular scenarios.
3. High stakes and low tolerance for hallucination
Finally, the business context raises the bar:
- Credit agreement summaries support risk, underwriting, and compliance decisions.
- A wrong or hallucinated answer is often worse than no answer at all.
This requires not just “good-enough” summaries, but grounded, verifiable outputs where every answer can be traced back to the underlying document text.
Ontra’s solution: relational RAG
A well-established technique in information systems for answering questions is Retrieval-Augmented Generation (RAG). RAG combines retrieval systems and language models for question-answering tasks. When a user poses a question, the system first searches through a knowledge base to retrieve the most relevant passages or chunks of information. These retrieved document passages are provided to the model, with the original question, to generate the answer.
In addition to being a proven approach, RAG inherently supports the qualities we value when answering questions, ensuring the answers are complete, grounded, and accurate.
A generic RAG approach, however, treats passages in isolation and misses cross-references and relationships. Credit agreements often reference other sections, and sometimes these relationships can be conditional, such as “notwithstanding the terms of Section 4.2,” and build on prior definitions, so these connections are important for accuracy.
To address these limitations, we enhanced the generic RAG workflow with a multi-hop relational retrieval approach that leverages document cross-references and hierarchy. It outperforms generic RAG by linking retrieved context to related definitions and sections, creating an interconnected retrieval structure that captures document relationships.
The critical role of systematic evaluation
While having a good workflow is essential, systematic evaluation is what transforms a research experiment into a production-ready system.
Without proper evaluation frameworks, it’s impossible to:
- Measure actual system performance.
- Identify bottlenecks and failure modes.
- Make data-driven improvements.
- Validate hypotheses about system changes.
Without such evaluation, teams are effectively operating blind — unable to distinguish meaningful progress from noise, prone to misattributing causes of success or failure, and at risk of shipping fragile systems that only appear reliable in controlled environments.
Robust evaluation infrastructure creates the feedback loop necessary for informed iteration, reproducibility, and long-term system integrity.
Evaluation framework
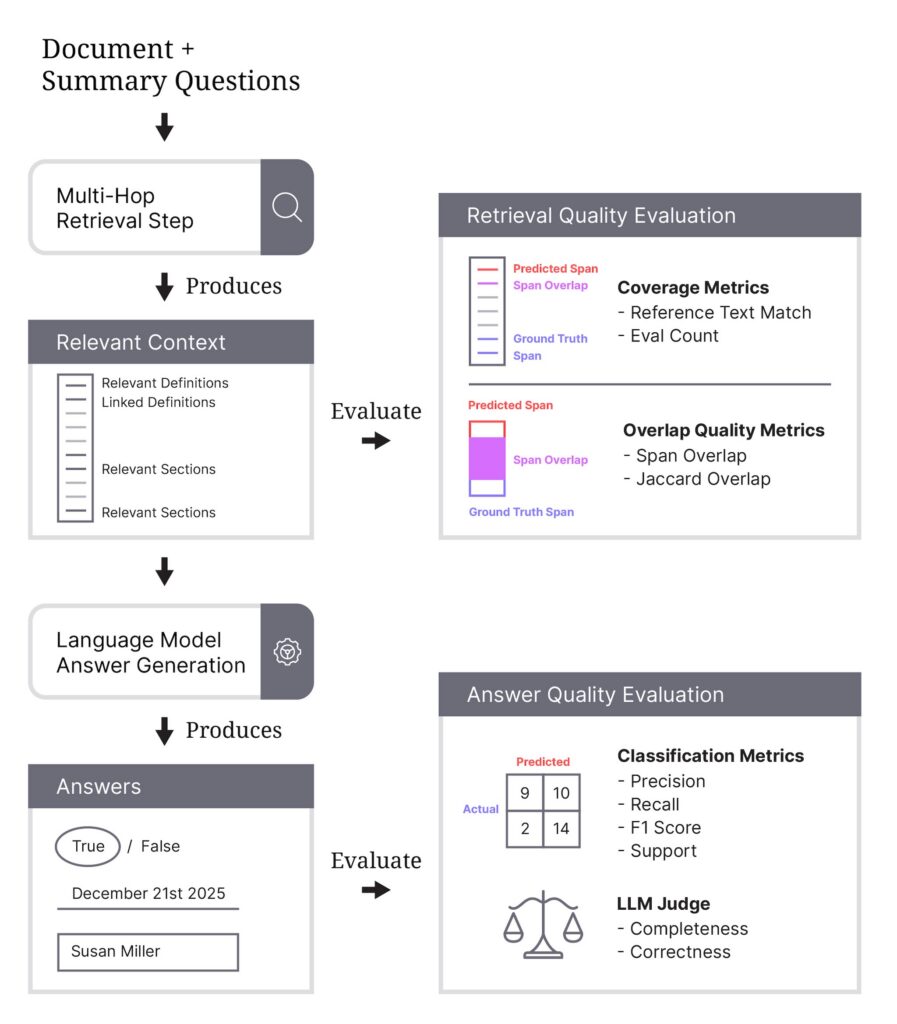
Evaluating context retrieval
One of the most important aspects of our evaluation framework is context retrieval evaluation: measuring how well we identify the exact location of answers within source documents. This is critical for assessing groundedness and ensuring answers are actually supported by document text.
Span retrieval enables:
- Answer Grounding: Users can verify answers against source text.
- Transparency: Legal teams can see exactly where information comes from.
- Error Detection: Incorrect spans reveal system issues.
Key metrics
Coverage metrics:
- Reference text success: Percentage of documents where the model provides span locations.
- Eval count: Number of documents evaluated.
Overlap quality metrics:
- Span overlap: Percentage of documents where predicted and ground truth spans overlap.
- Jaccard overlap span mean: Average overlap quality (IoU) when spans are found, showing accuracy of span locations.
Multi-reference metrics:
For questions with multiple answer spans:
- Multi-reference text f1: Balanced measure of how well the model identifies all relevant spans.
Many questions have multiple valid answer spans (e.g., “Debt Service Coverage Ratio” appears in both definitions and covenants, as shown in the image), making multi-reference metrics essential for comprehensive evaluation.
Evaluating answer generation
For evaluating the quality of our final answers, we use classification metrics: Precision, Recall, F1, and Support — the industry-standard metrics for evaluating model performance. These metrics provide a comprehensive view of our system’s accuracy across different question types.
Why classification metrics for QA
We treat question answering as a classification problem by comparing predicted answers against ground truth annotations:
- Precision: Of all the answers our model predicted, what percentage were correct? High precision means the model rarely provides incorrect answers.
- Recall: Of all the correct answers in the ground truth, what percentage did our model find? High recall means the model rarely misses correct answers.
- F1 Score: The harmonic mean of precision and recall, providing a balanced measure that penalizes extreme trade-offs between the two.
- Support: The number of ground truth instances for each answer value, helping us understand class distribution and identify data imbalances.
These metrics are well-understood, widely accepted, and provide clear benchmarks for improvement.
Handling different answer types
Our system evaluates multiple answer types:
Boolean Questions
(e.g., “Does the agreement contain a material adverse change clause?”)
We compute metrics separately for True and False classes, which helps identify imbalances. If True answers perform worse with low support, we can prioritize improving detection of these rarer cases.
Integer/Date Questions
(e.g., “What is the maximum number of amendments?”, “What is the effective date?”)
These are evaluated as exact matches after normalization. For integers, each unique value is a separate class. Dates are standardized to YYYY-MM-DD format.
Free Text Questions
(e.g., “Who is the borrower?”, “Extract and summarize information about the ‘Compliance Certificate Delivery’”)
These answers often include formatting differences, nuanced language, or multi-sentence explanations that don’t map cleanly to a single canonical string. To evaluate them reliably, we use an LLM Judge — a separate, purpose-built model that scores the correctness and completeness of generated answers. The judge receives the question, the model-predicted answer, and the ground-truth answer and makes an evaluation on whether the answer is correct and complete.
This approach ensures accurate performance measurement across the diverse question types in credit agreement summarization.
The improvement cycle
A structured evaluation cycle that analyzes metrics, forms hypotheses, refines prompts, re-runs evaluations, deploys improvements, and monitors outcomes is more effective than relying on qualitative spot checks (vibe checks) because it replaces intuition with evidence.
Spot checks depend on a few hand-picked examples and subjective judgments, which cannot uncover systematic errors, blind spots, or regressions. In contrast, a systematic improvement cycle provides measurable performance across a representative test set, isolates the root causes of failures, and ensures that changes actually improve results rather than shifting errors elsewhere. It also creates an auditable pathway for continuous improvement, allowing our teams to deploy updates confidently and track real-world impact. In high-stakes domains, quality cannot depend on quick impressions but on whether outputs consistently meet objective standards.
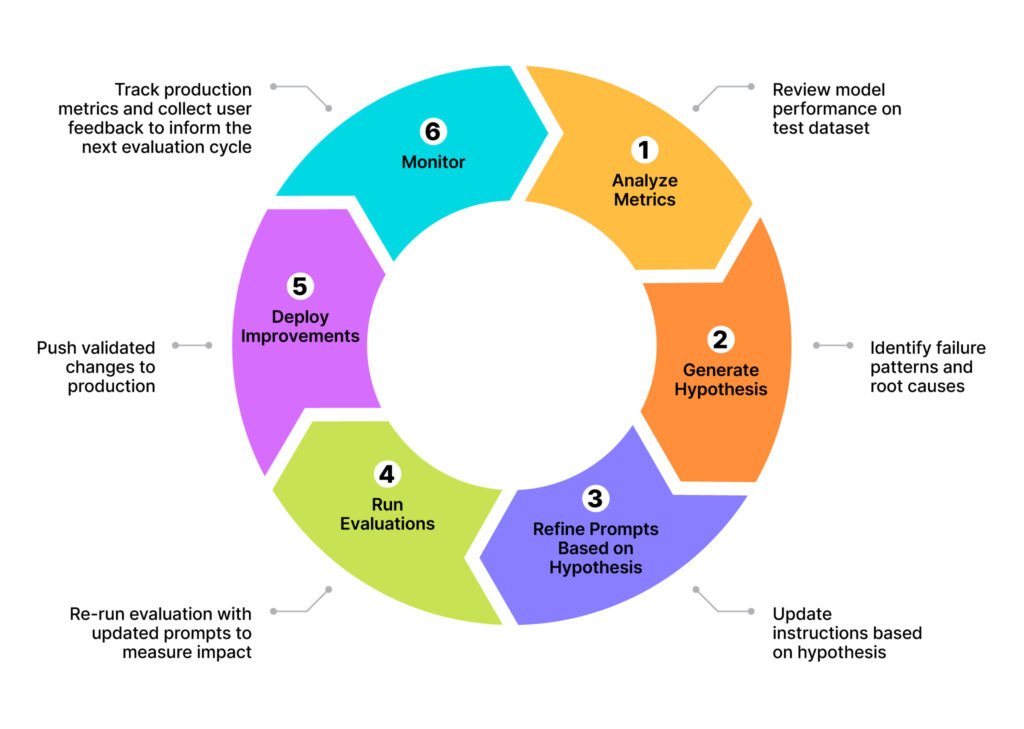
- Analyze metrics: Review performance across all metrics on test dataset.
- Generate hypothesis: Identify patterns and form hypotheses about what’s causing errors.
- Refine prompts based on hypothesis: Update system instructions and prompts based on insights.
- Run evaluations: Re-run evaluations with updated prompts to measure impact.
- Deploy improvements: Push validated improvements to production.
- Monitor: Track production metrics and collect user feedback to inform the next cycle.
Examples of systematic improvements
Domain-guided prompt optimization
- Hypothesis: Incorporating legal-domain language and task-specific instructions into prompts will improve both span retrieval and question-answering accuracy.
- Approach: SMEs collaborate with ML engineers to iteratively design, test, and refine prompts that capture nuanced legal reasoning and document structure.
- Evaluation & analysis: Quantitatively measure how domain-informed phrasing impacts retrieval precision and answer quality across benchmark datasets.
Context retrieval strategy experiments
- Hypothesis: In Multi-Hop Retrieval, different context assembly and relationship-linking methods will improve model comprehension and response reliability.
- Approach: ML engineers design controlled experiment using a different retrieval methodology guided by SME insights into document organization and relevance.
- Evaluation & analysis: Quantitatively measure how new retrieval methodology compares to the current retrieval methodology.
Real-world impact and results
Since implementing this systematic evaluation approach (over ~3 months since launch), we’ve achieved:
- 46% improvement in overall F1-Score
- 66% increase in questions achieving F1 score greater than 0.9
- 93% retrieval recall
- 26% reduction in answers requiring human corrections
More importantly, the evaluation framework has enabled us to:
- Quickly identify and fix edge cases
- Confidently deploy system updates
- Provide transparent performance metrics to stakeholders
- Build trust with end users through explainable results
Conclusion and key takeaways
Building a production-grade credit agreement summarization system demands more than technical sophistication — it requires a disciplined, evaluation-first mindset. Systematic evaluation is the foundation that guides model insight and development based on performance metrics. It enables continuous improvement, builds user trust, and ensures reliable performance in high-stakes applications.
- Be evaluation-driven: Use comprehensive, systematic evaluation as the foundation for model development and iteration.
- Measure at every level: Assess performance across each stage of the pipeline, not just the end output, to surface targeted improvement opportunities.
- Leverage domain expertise: Involve SMEs throughout prompt engineering, evaluation design, and result interpretation to align model behavior with real-world needs.
- Prioritize transparency: Grounded answers and reference text build user trust essential for production adoption.
Our framework illustrates how combining domain expertise with rigorous evaluation leads to systems that not only perform well but also deliver measurable value in practice. Evaluating at every stage of the pipeline, applying consistent metrics, and fostering tight collaboration between technical and subject-matter teams create a sustainable path toward dependable AI systems.
As the industry moves deeper into AI-assisted document understanding, the organizations that invest early in robust evaluation and human–machine collaboration will set the standard. By embedding transparency and rigor into our approach today, we’re laying the groundwork for intelligent systems that legal and financial professionals can trust, verify, and rely on in their most critical decisions.







